d-Matrix Tantang HBM untuk Komputasi AI Tercepat
3D in-memory compute digadang 10x lebih cepat dari HBM untuk inference.
Arsitektur baru memangkas latensi dengan memindah komputasi ke dalam memori.
Jika klaim akurat, biaya dan daya inference bisa anjlok drastis.
Kenapa HBM Bisa Kewalahan untuk Inference?
HBM adalah tulang punggung komputasi AI modern, terutama untuk training model besar. Dengan menumpuk die memori secara vertikal, HBM menghadirkan bandwidth tinggi yang vital saat melahap batch data raksasa. Namun pada fase inference, pola akses berbeda: beban sering kali lebih sensitif terhadap latensi dan efisiensi saat mengeksekusi operasi matriks-vektor berulang dengan ukuran lebih kecil dan volatilitas tinggi.
Di skenario produksi, inference juga dijalankan dalam skala besar, tersebar, dan hemat biaya. Di titik ini, setiap siklus yang dihemat pada perjalanan data antara compute dan memori berdampak nyata pada biaya dan konsumsi energi. Inilah celah yang coba diisi oleh pendekatan digital in-memory compute.
Pergeseran fokus dari “semua di GPU” ke desain memori yang ikut “berpikir” menandai tren arsitektur: spesialisasi hardware sesuai beban kerja. Jika training butuh throughput gila-gilaan, inference lebih butuh pipeline yang rapat, ringkas, dan hemat daya.
3DIMC: Komputasi Tepat di Dalam Memori
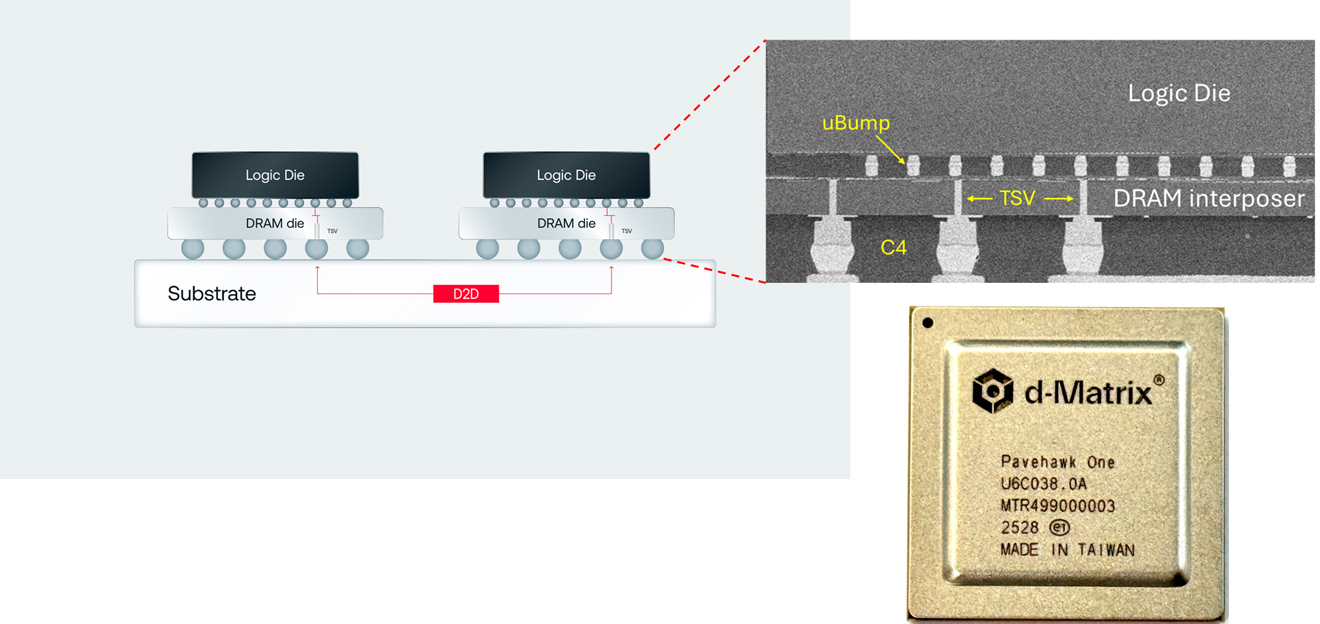
d-Matrix memperkenalkan 3D digital in-memory compute (3DIMC), yang pada generasi Pavehawk menggabungkan die LPDDR5 dengan chiplet logic DIMC di atas interposer. Alih-alih memindahkan data ke prosesor, sebagian komputasi—terutama operasi matriks-vektor khas transformer—dilakukan di dekat atau di dalam tumpukan memori.
Kuncinya adalah kedekatan data dan compute. Dengan memotong jarak dan hop interkoneksi, latensi bisa ditekan, bandwidth efektif meningkat, dan energi per operasi turun. d-Matrix mengklaim generasi penerus, Raptor, dapat mengungguli HBM hingga 10x pada beban inference sambil memangkas daya hingga 90%.
Pendekatan chiplet memudahkan evolusi: logic DIMC disetel untuk kernel yang dominan di inference, sementara memori standar seperti LPDDR5 memberikan ketersediaan dan biaya yang lebih ramah. Arsitektur ini memanfaatkan kenyataan bahwa inferensi didominasi lookup dan operasi linier yang berulang.
Janji Kinerja vs Realitas Integrasi
Klaim “10x lebih cepat” terdengar ambisius, tetapi kredibilitasnya bergantung pada tiga hal: pola workload, ukuran dan bentuk model, serta integrasi perangkat lunak. Untuk mendapatkan lompatan orde-besar, pipeline harus dioptimalkan end-to-end: scheduler, layout tensor, kuantisasi, hingga operator yang di-fuse ke dalam DIMC.
Di atas kertas, model transformer dengan rasio tinggi operasi matriks-vektor akan sangat diuntungkan. Namun variasi arsitektur model, teknik kompresi, dan kebutuhan presisi bisa mengubah profil performa. Tanpa toolchain matang, keuntungan hardware bisa tergerus overhead.
Karena itu, keberhasilan 3DIMC akan ditentukan oleh ekosistem: compiler yang memetakan graph ke DIMC, runtime yang cerdas, serta dukungan framework populer. Adopsi enterprise juga menuntut metrik konsisten dan benchmark terbuka agar perbandingan dengan HBM dan GPU konvensional adil.
Ekonomi Compute: Hemat Daya, Hemat Biaya
Jika benar mampu memangkas konsumsi daya hingga 90% pada beban inference, implikasinya besar bagi hyperscaler. Biaya energi adalah komponen utama TCO. Pengurangan daya memperpanjang kapasitas rak yang ada, menurunkan kebutuhan pendinginan, dan membuka ruang headroom untuk beban lain. Dengan biaya memori non-HBM yang cenderung lebih rendah dan rantai pasok lebih luas, total biaya sistem dapat turun signifikan.
Selain itu, ketergantungan pada beberapa pemasok HBM dengan harga premium menjadi risiko bisnis. Alternatif yang layak secara performa dan biaya akan menyeimbangkan daya tawar pasar dan mengurangi bottleneck supply.
Jalan ke Depan: Dari Lab ke Produksi
Saat ini Pavehawk telah berjalan di laboratorium d-Matrix, dengan Raptor direncanakan sebagai lompatan performa berikutnya. Pola yang terlihat sejalan dengan tren industri: mengembangkan hardware khusus tugas untuk memaksimalkan efisiensi. Jika hasil pengujian independen menegaskan klaim, kita bisa melihat arsitektur campuran di pusat data: GPU HBM untuk training, 3DIMC untuk inference skala besar.
Tantangannya tetap ada: memastikan kompatibilitas software, menyediakan SDK yang stabil, serta membuktikan reliabilitas jangka panjang dalam SLA ketat. Ketersediaan kapasitas produksi dan dukungan vendor integrator juga akan menjadi faktor adopsi.
Pada akhirnya, d-Matrix menyoroti tesis penting: masa depan AI tidak tunggal. Bukan GPU vs memori, melainkan orkestrasi perangkat yang tepat untuk beban yang tepat—dengan efisiensi sebagai penentu pemenang.
(Burung Hantu Infratek / Berbagai Sumber)
Berita ini 100% diriset, ditulis dan dikembangkan oleh AI internal Burung Hantu Infratek. Bisa jadi terdapat kesalahan pada data aktual.